Erstellen Sie einen perfekten Blog mit FastAPI: Volltextsuche für Beiträge
Wenhao Wang
Dev Intern · Leapcell

Im vorherigen Artikel haben wir unseren Blogbeiträgen eine Bild-Upload-Funktion hinzugefügt.
Mit der Zeit können Sie sich vorstellen, dass Ihr Blog eine beträchtliche Anzahl von Artikeln angesammelt hat. Ein neues Problem taucht nach und nach auf: Wie können Leser die Artikel, die sie lesen möchten, schnell finden?
Die Antwort ist natürlich die Suche.
In diesem Tutorial fügen wir unserem Blog eine Volltextsuchfunktion hinzu.
Möglicherweise denken Sie sich: Kann ich nicht einfach eine SQL-Abfrage vom Typ LIKE '%keyword%' verwenden, um die Suche zu implementieren?
Für einfache Szenarien können Sie das natürlich. LIKE-Abfragen sind jedoch bei der Verarbeitung großer Textblöcke leistungsschwach und können keine Fuzzy-Suchen durchführen (z. B. wird bei der Suche nach "creation" nicht nach "create" gesucht).
Daher werden wir eine effizientere Lösung verfolgen: die Nutzung der integrierten Volltextsuchfunktion (FTS) von PostgreSQL. Sie ist nicht nur schnell, sondern unterstützt auch Funktionen wie Stemming und Relevanzbewertung, wodurch Suchfunktionen weit überlegen sind als LIKE.
Schritt 1: Suchinfrastruktur der Datenbank
Um die FTS-Funktion von PostgreSQL zu nutzen, müssen wir zunächst einige Änderungen an unserer post-Tabelle vornehmen. Die Kernidee besteht darin, eine spezielle Spalte zu erstellen, die speziell für die Speicherung optimierter Textdaten bestimmt ist, die mit hoher Geschwindigkeit durchsucht werden können.
Kernkonzept: tsvector
Wir fügen der post-Tabelle eine neue Spalte vom Typ tsvector hinzu. Diese zerlegt den Titel und Inhalt eines Artikels in einzelne Wörter (Lexeme) und normalisiert sie (z. B. Verarbeitung von "running" und "ran" zu "run") für spätere Abfragen.
Ändern der Tabellenstruktur
Führen Sie die folgende SQL-Anweisung in Ihrer PostgreSQL-Datenbank aus, um die Spalte search_vector zur post-Tabelle hinzuzufügen.
ALTER TABLE "post" ADD COLUMN "search_vector" tsvector;
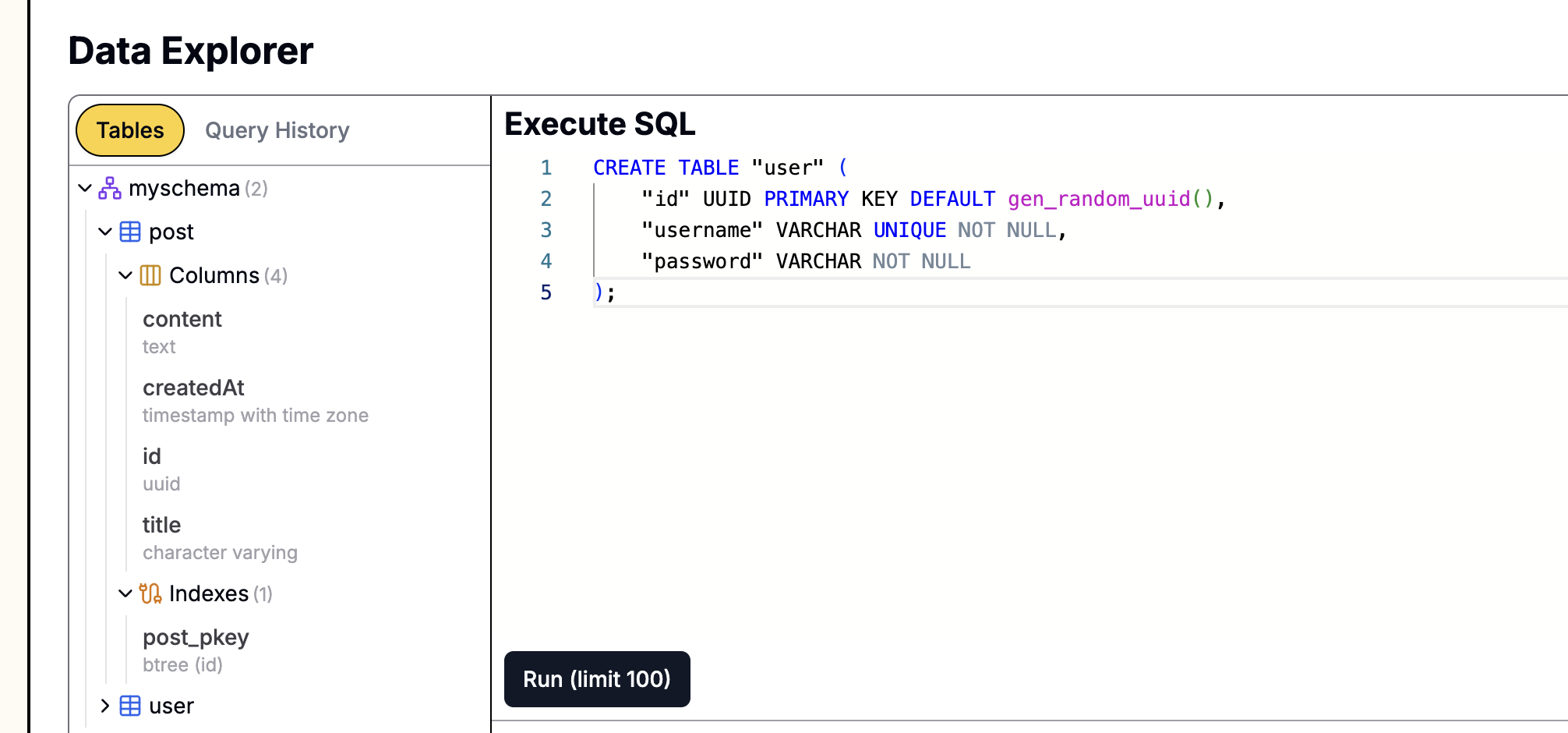
Wenn Ihre Datenbank auf Leapcell erstellt wurde,

können Sie SQL-Anweisungen einfach über die grafische Oberfläche ausführen. Gehen Sie einfach zur Seite "Datenbankverwaltung" auf der Website, fügen Sie die obige Anweisung in die SQL-Schnittstelle ein und führen Sie sie aus.
Aktualisieren des Suchvektors für vorhandene Beiträge
Die Aktualisierung des Suchvektors (search_vector) für Beiträge macht diese durchsuchbar.
Da Ihr Blog bereits einige Artikel enthält, können Sie einfach die folgende SQL-Anweisung ausführen, um search_vector-Daten für diese zu generieren:
UPDATE "post" SET search_vector = setweight(to_tsvector('english', coalesce(title, '')), 'A') || setweight(to_tsvector('english', coalesce(content, '')), 'B');
Automatische Aktualisierungen mit einem Trigger
Niemand möchte die Spalte search_vector manuell aktualisieren, jedes Mal wenn ein Beitrag erstellt oder aktualisiert wird. Der beste Weg ist, die Datenbank diese Arbeit automatisch erledigen zu lassen. Dies kann durch das Erstellen eines Triggers erreicht werden.
Erstellen Sie zunächst eine Funktion, die, genau wie die obige Abfrage, die search_vector-Daten für einen Beitrag generiert.
CREATE OR REPLACE FUNCTION update_post_search_vector() RETURNS TRIGGER AS $$ BEGIN NEW.search_vector := setweight(to_tsvector('english', coalesce(NEW.title, '')), 'A') || setweight(to_tsvector('english', coalesce(NEW.content, '')), 'B'); RETURN NEW; END; $$ LANGUAGE plpgsql;
Die Funktion
setweightermöglicht es Ihnen, Text aus verschiedenen Feldern unterschiedliche Gewichtungen zuzuweisen. Hier haben wir das Gewicht des Titels ('A') höher als das des Inhalts ('B') gesetzt. Das bedeutet, dass in den Suchergebnissen Artikel mit dem Schlüsselwort im Titel höher eingestuft werden.
Erstellen Sie als Nächstes einen Trigger, der die gerade erstellte Funktion automatisch aufruft, wenn ein neuer Beitrag eingefügt (INSERT) oder aktualisiert (UPDATE) wird.
CREATE TRIGGER post_search_vector_update BEFORE INSERT OR UPDATE ON "post" FOR EACH ROW EXECUTE FUNCTION update_post_search_vector();
Erstellen eines Suchindexes
Schließlich müssen wir einen GIN-Index (Generalized Inverted Index) für die Spalte search_vector erstellen, um die Suchleistung sicherzustellen.
CREATE INDEX post_search_vector_idx ON "post" USING gin(search_vector);
Jetzt ist Ihre Datenbank bereit für die Suche. Sie verwaltet automatisch einen effizienten Suchindex für jeden Artikel.
Schritt 2: Erstellen der Suchlogik in FastAPI
Nachdem die Datenbankebene vorbereitet ist, kehren wir zu unserem FastAPI-Projekt zurück, um den Backend-Code für die Verarbeitung von Suchanfragen zu schreiben.
Erstellen der Suchroute
Wir fügen die suchbezogene Logik direkt in die Datei routers/posts.py ein. Da SQLModel auf SQLAlchemy basiert, können wir die text()-Funktion von SQLAlchemy verwenden, um rohe SQL-Abfragen auszuführen.
Öffnen Sie routers/posts.py und nehmen Sie folgende Änderungen vor:
# routers/posts.py import uuid from fastapi import APIRouter, Request, Depends, Form, Query from fastapi.responses import HTMLResponse, RedirectResponse from fastapi.templating import Jinja2Templates from sqlmodel import Session, select from sqlalchemy import text # Import the text function from database import get_session from models import Post from auth_dependencies import get_user_from_session, login_required import comments_service import markdown2 router = APIRouter() templates = Jinja2Templates(directory="templates") # ... other routes ... @router.get("/posts/search", response_class=HTMLResponse) def search_posts( request: Request, q: str = Query(None), # Get the search term from query parameters session: Session = Depends(get_session), user: dict | None = Depends(get_user_from_session) ): posts = [] if q: # Convert user input (e.g., "fastapi blog") to a format # to_tsquery can understand ("fastapi & blog") search_query = " & ".join(q.strip().split()) # Use raw SQL for full-text search statement = text(""" SELECT id, title, content, "createdAt" FROM post WHERE search_vector @@ to_tsquery('english', :query) ORDER BY ts_rank(search_vector, to_tsquery('english', :query)) DESC "") results = session.exec(statement, {"query": search_query}).mappings().all() posts = list(results) return templates.TemplateResponse( "search-results.html", { "request": request, "posts": posts, "query": q, "user": user, "title": f"Search Results for '{q}'" } ) # Ensure this route is placed after /posts/search to avoid route conflicts @router.get("/posts/{post_id}", response_class=HTMLResponse) def get_post_by_id( # ... function content remains the same # ...
Code Explanation:
- Wir fügen
from sqlalchemy import textam Anfang der Datei hinzu. - Eine neue Route
/posts/searchwird hinzugefügt. Um Konflikte mit der Route/posts/{post_id}zu vermeiden, stellen Sie sicher, dass diese neue Route vor der Routeget_post_by_idplatziert wird. q: str = Query(None): FastAPI erhält den Wert vonqaus der URL-Query-Zeichenfolge (z. B./posts/search?q=keyword).to_tsquery('english', :query): Diese Funktion konvertiert die vom Benutzer bereitgestellte Suchzeichenfolge in einen speziellen Abfragetyp, der mit einertsvector-Spalte abgeglichen werden kann. Wir verwenden&, um mehrere Wörter zu verbinden, was bedeutet, dass alle Wörter übereinstimmen müssen.@@-Operator: Dies ist der "Übereinstimmungs"-Operator für die Volltextsuche. Die ZeileWHERE search_vector @@ ...ist der Kern der Suchoperation.ts_rank(...): Diese Funktion berechnet eine "Relevanzbewertung" basierend darauf, wie gut die Abfrageterme mit dem Blogbeitrag übereinstimmen. Wir sortieren nach diesem Rang in absteigender Reihenfolge, um sicherzustellen, dass die relevantesten Artikel zuerst erscheinen.session.exec(statement, {"query": search_query}).mappings().all(): Wir führen die rohe SQL-Abfrage aus und verwenden.mappings().all(), um die Ergebnisse in eine Liste von Wörterbüchern umzuwandeln, was die Verwendung in der Vorlage erleichtert.
Schritt 3: Integrieren der Suchfunktionalität in das Frontend
Die Backend-API ist bereit. Fügen wir nun eine Suchbox und eine Suchergebnisseite zu unserer Benutzeroberfläche hinzu.
Hinzufügen der Suchbox
Öffnen Sie die Datei templates/_header.html und fügen Sie ein Suchformular zur Navigationsleiste hinzu.
<header> <h1><a href="/">My Blog</a></h1> <nav> <form action="/posts/search" method="GET" class="search-form"> <input type="search" name="q" placeholder="Search posts..." required> <button type="submit">Search</button> </form> {% if user %} <span class="welcome-msg">Welcome, {{ user.username }}</span> <a href="/posts/new" class="new-post-btn">New Post</a> <a href="/auth/logout" class="nav-link">Logout</a> {% else %} <a href="/users/register" class="nav-link">Register</a> <a href="/auth/login" class="nav-link">Login</a> {% endif %} </nav> </header>
Erstellen der Suchergebnisseite
Erstellen Sie eine neue Datei namens search-results.html im Verzeichnis templates. Diese Seite wird verwendet, um die Suchergebnisse anzuzeigen.
{% include "_header.html" %} <div class="search-results-container"> <h2>Search Results for: "{{ query }}"</h2> {% if posts %} <div class="post-list"> {% for post in posts %} <article class="post-item"> <h2><a href="/posts/{{ post.id }}">{{ post.title }}</a></h2> <p>{{ post.content[:150] }}...</p> <small>{{ post.createdAt.strftime('%Y-%m-%d') }}</small> </article> {% endfor %} </div> {% else %} <p>No posts found matching your search. Please try different keywords.</p> {% endif %} </div> {% include "_footer.html" %}
Ausführen und Testen
Starten Sie Ihre Anwendung neu:
uvicorn main:app --reload
Öffnen Sie Ihren Browser und navigieren Sie zur Homepage Ihres Blogs.
Schreiben wir einen neuen Artikel, der das Schlüsselwort "testing" enthält.
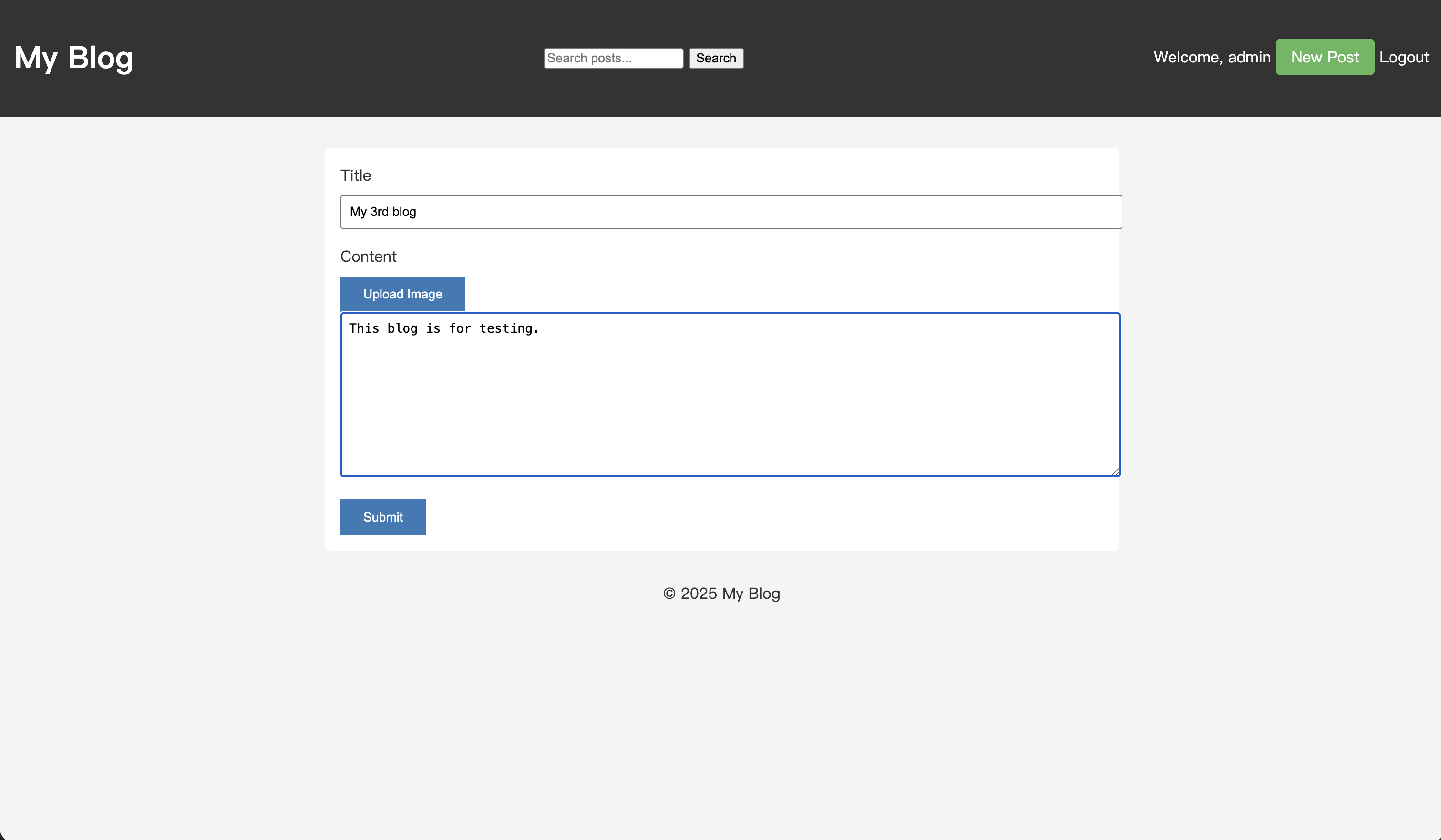
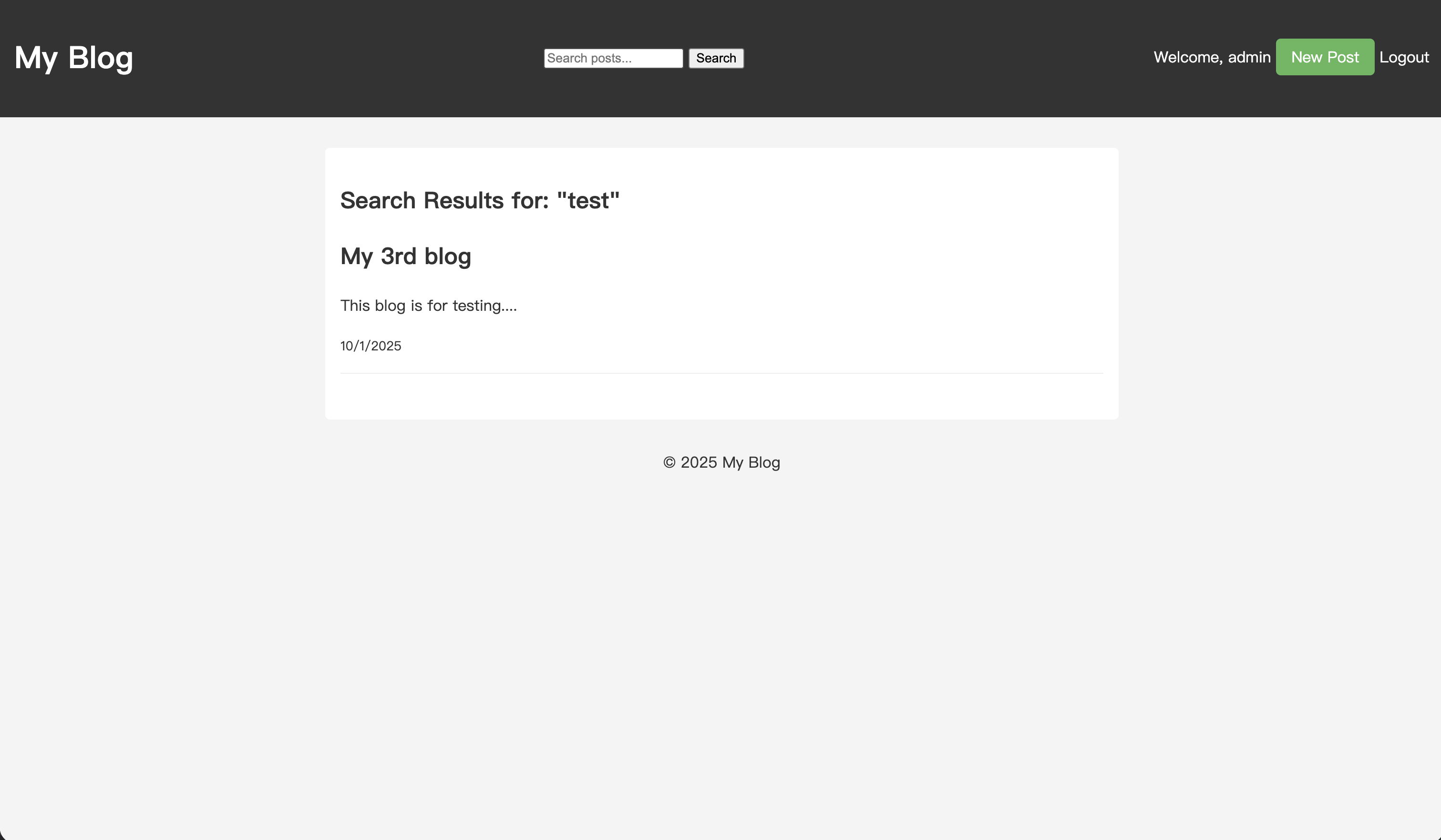
Nachdem Sie den Beitrag gespeichert haben, geben Sie "test" in das Suchfeld ein und führen Sie eine Suche durch.
Auf der Suchergebnisseite erscheint nun der gerade erstellte Artikel in den Ergebnissen.
Ihr Blog unterstützt jetzt eine Volltextsuchfunktion. Egal wie viel Sie schreiben, Ihre Leser werden sich nicht mehr verirren.